Boas, pessoal. Mais uma vez voltando dos mortos, agora vou falar um pouco sobre sumarização automática de textos.
Começando
Bom, sumarização de textos é isso mesmo que você entendeu. Tem um texto grande e a ideia é criar um texto menor, mantendo o importante da informação. Agora só falta dizer que raios é ‘extração’ e, pior ainda, que maldito grafo é esse.
Tem um montão de jeitos de se resumir (sumarizar) um texto, sendo que os mais usados atualmente são os que baseados em análises estatísticas criam um sumário extraindo as frases principais dos texto-fonte [1]. Dentre estes, segundo [2] e [3], os que se saem melhor são os baseados em aprendizagem de máquina, isto é, que usam uma massa de dados catalogada para treinamento e a avaliação dos textos é feita com base nos resultados deste treinamento, e os baseados em grafos, que criam grafos à partir do texto-fonte e fazem a análise baseada nos nós e arestas 1 2.
Agora que a gente já sabe o que é extração e sabe que o grafo é o que será construído com base no texto para, com base nele, decidirmos que frase extrair, vamos olhar mais de perto como funciona essa tal de extração de sentenças baseada em grafos 3.
Textos como grafos
A primeira coisa a se fazer quando trabalhando com grafos é identificar quais unidades de texto iremos usar como os nós do grafo e quais as relações entre estas unidades usaremos para criar as arestas. As características dos nós e arestas serão diferentes de aplicação para aplicação, mas independente das características dos nós e arestas, a aplicação de grafos a textos de linguagem natural consiste, de modo geral, nos seguintes passos [5]:
1) Identificar as unidades de texto (tokens) que melhor se encaixam no trabalho corrente e colocá-las como nós do grafo.
2) Identificar as relações que conectam estas unidades de texto e criar arestas, baseadas nestas relações, entre os nós do grafo.
3) Iterar o algorítimo escolhido para se pontuar os nós.
4) Ordenar os nós de acordo com a pontuação final. Usar esta pontuação para classificação/extração.
Um grafo para extração de sentenças
Como o nosso objetivo aqui é criar um sumarizador por extração, nossa tarefa é determinar quais são as sentenças mais relevantes do texto e depois usá-las para criar o resumo. Sendo assim, usaremos sentenças inteiras como nós e as arestas entre estes nós serão construídas baseadas na semelhança entre as sentenças. Desta maneira será criado um grafo não-orientado relacionando as sentenças entre si. É importante ressaltar também que, pelo menos no contexto da linguagem natural, é interessante além de considerar-se a quantidade de relações, considerar-se também a ‘força’ destas relações, atribuindo algum peso a elas [4].
A semelhança entre duas sentenças pode ser determinada pelo número de tokens que se repetem nestas frases. Para evitar-se dar notas mais altas a sentenças grandes, usa-se um fator de normalização que dividade a o número de repetições de token pelo tamanho das sentenças. Formalmente, dadas duas sentenças Si e Sj com uma sentença sendo representada pelo conjunto de Ni palavras que aparecem na sentença: Si = Wi1, Wi2… Win, a semelhança entre Si e Sj é definida como [4]:
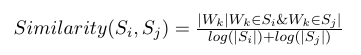
Com estas informações que temos até agora já podemos implementar um código que cria um grafo baseado em um texto, ou seja, os passos 1 e 2, mas ainda nos falta escolher um algorítimo para dar uma pontuação aos nós e, por fim, extrair as frases mais relevantes. Para facilitar a nossa implementação, em princípio vamos usar um algorítimo bem simples para pontuar as sentenças 4.
Neste algorítimo simplificado, a pontuação dos nós será simplesmente a soma do peso das relações que este nó tem com os outros, ou seja, a pontuação dos nós e a soma do peso as arestas relacionadas à ele. Formalmente, sendo Rel(Si) o conjunto nós relacionados à sentença Si e wij sendo o peso da relação entre Si e Sj, a pontuação de de um nó do grafo é definida como:
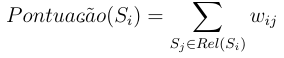
Com isso, agora já temos também estabelecido como faremos o passo 3. O passo 4 é simples e não requer maiores explicações.
Implementando o sumarizador simplificado
Nosso grafo consistirá em nós sendo as sentenças de um texto e as arestas sendo a semelhança entre as sentenças. Para a implementação, usaremos a linguagem de programação Python [6] em conjunto com algumas bibliotecas. São elas: NLTK [7] e NetworkX [8].
Então, antes de começar, vamos relembrar o que devemos fazer: Primeiro, vamos decompor o texto em sentenças e as sentenças em palavras. Depois disso feito, colocaremos as sentenças como os nós do grafo e as arestas serão feitas baseadas na semelhança entre as frases. Com o grafo já criado, daremos uma pontuação para os nós e por fim extrairemos as sentenças de maior pontuação 5.
Agora, deixa de papo e vamos pro que importa: o código!
# -*- coding: utf-8 -*- import math import nltk import networkx as nx class Texto: def __init__(self, raw_text): """ ``raw_text`` é o text puro a ser resumido. """ self.raw_text = raw_text self._sentences = None self._graph = None def resumir(self): """ Aqui a gente extrai as frases com maior pontuação. O tamanho do resumo será 20% do número de frases original """ # aqui definindo a quantidade de frases qtd = int(len(self.sentences) * 0.2) or 1 # ordenando as frases de acordo com a pontuação # e extraindo a quantidade desejada. sentencas = sorted( self.sentences, key=lambda s: s.pontuacao, reverse=True)[:qtd] # ordenando as sentenças de acordo com a ordem no texto # original. ordenadas = sorted(sentencas, key=lambda s: self.sentences.index(s)) return ' '.join([s.raw_text for s in ordenadas]) @property def sentences(self): """ Quebra o texto em sentenças utilizando o sentence tokenizer padrão do nltk. """ if self._sentences is not None: return self._sentences # nltk.sent_tokenize é quem divide o texto em sentenças. self._sentences = [Sentenca(self, s) for s in nltk.sent_tokenize(self.raw_text)] return self._sentences @property def graph(self): """ Aqui cria o grafo, colocando as sentenças como nós as arestas (com peso) são criadas com base na semelhança entre sentenças. """ if self._graph is not None: return self._graph graph = nx.Graph() # Aqui é o primeiro passo descrito acima. Estamos criando os # nós com as unidades de texto relevantes, no nosso caso as # sentenças. for s in self.sentences: graph.add_node(s) # Aqui é o segundo passo. Criamos as arestas do grafo # baseadas nas relações entre as unidades de texto, no nosso caso # é a semelhança entre sentenças. for node in graph.nodes(): for n in graph.nodes(): if node == n: continue semelhanca = self._calculate_similarity(node, n) if semelhanca: graph.add_edge(node, n, weight=semelhanca) self._graph = graph return self._graph def _calculate_similarity(self, sentence1, sentence2): """ Implementação da fórmula de semelhança entre duas sentenças. """ w1, w2 = set(sentence1.palavras), set(sentence2.palavras) # Aqui a gente vê quantas palavras que estão nas frases se # repetem. repeticao = len(w1.intersection(w2)) # Aqui a normalização. semelhanca = repeticao / (math.log(len(w1)) + math.log(len(w2))) return semelhanca class Sentenca: def __init__(self, texto, raw_text): """ O parâmetro ``texto`` é uma instância de Texto. ``raw_text`` é o texto puro da sentença. """ self.texto = texto self.raw_text = raw_text self._palavras = None self._pontuacao = None @property def palavras(self): """ Quebrando as sentenças em palavras. As palavras da sentença serão usadas para calcular a semelhança. """ if self._palavras is not None: return self._palavras # nltk.word_tokenize é quem divide a sentenças em palavras. self._palavras = nltk.word_tokenize(self.raw_text) return self._palavras @property def pontuacao(self): """ Implementação do algorítimo simplificado para pontuação dos nós do grafo. """ if self._pontuacao is not None: return self._pontuacao # aqui a gente simplesmente soma o peso das arestas # relacionadas a este nó. pontuacao = 0.0 for n in self.texto.graph.neighbors(self): pontuacao += self.texto.graph.get_edge_data(self, n)['weight'] self._pontuacao = pontuacao return self._pontuacao def __hash__(self): """ Esse hash aqui é pra funcionar como nó no grafo. Os nós do NetworkX tem que ser 'hasheáveis' """ return hash(self.raw_text)
Para testar vamos resumir o seguinte texto, extraído do jornal Folha de São Paulo:
Dezenas de veículos foram incendiados em frente a sede do governo da região de Guerrero, no México, em um protesto pelo desaparecimento e morte de 43 estudantes da escola normal rural de Ayotzinapa.
Mais de 300 jovens, a maioria com o rosto coberto, atacaram a fachada do edifício em Chipancingo, capital de Guerrero.
O protesto ocorreu após o procurador-geral da República do país, Jesús Murillo Karam, informar que três homens suspeitos de ser integrantes do cartel Guerreros Unidos confessaram ter matado os estudantes e queimado seus corpos. O presidente Enrique Peña Nieto prometeu na sexta (7) punir todos os responsáveis pelos “crimes abomináveis”.
Os jovens sumiram em 26 de setembro, depois de arrecadar fundos para a escola em Iguala (a 192 km da Cidade do México).
Na saída da cidade, dois ônibus que voltavam à instituição com os alunos foram alvejados por policiais e traficantes do Guerreros Unidos. O ataque deixou seis mortos.
Os confessores, identificados como Particio Reyes, Jonathan Osorio e Agustín García Reyes, dizem que receberam os 43 estudantes no lixão de Cocula, a 22 km de Iguala. Segundo os pistoleiros, 15 deles chegaram ao local mortos com sinais de asfixia.
Segundo a Procuradoria-Geral do México, os detidos não disseram quem levou os estudantes e quem era o mandante da emboscada.
O órgão, porém, acredita que o mandante foi o prefeito de Iguala, Jose Luis Abarca, preso na quarta (5).
A intenção seria evitar que os alunos atrapalhassem um evento em que sua mulher, María de los Ángeles Pineda, seria lançada como candidata a sucedê-lo. A mulher de Abarca é irmã de três chefes do Guerreros Unidos.
FAMILIARES
Em entrevista, os parentes disseram não acreditar na versão do procurador-geral e pediram que o material recolhido seja analisado por peritos independentes.
Para eles, o governo quer fazer com que eles acreditem que seus filhos estão mortos. “Sequer mostraram fotos dos nossos filhos. Enquanto não houver provas, nossos filhos estão vivos”, disse Felipe de la Cruz, pai de um dos alunos.
Os pais pediram ao governo que prossiga com as buscas e permita a assistência técnica da Comissão Interamericana de Direitos Humanos.
Agora, para usar o código, num shell de python, importe o módulo, crie uma instância da classe Texto e use o método resumir(), assim:
>>> import sumarizacao >>> t = sumarizacao.Texto(txt) >>> resumo = t.resumir()
Aqui a representação do grafo gerado. A largura das arestas é baseada na força das relações entre as frases e o tamanho dos nós é baseado na pontuação destes e o número dentro dos nós é índice da sentença no texto. Ao lado o resumo gerado pelo nosso código.
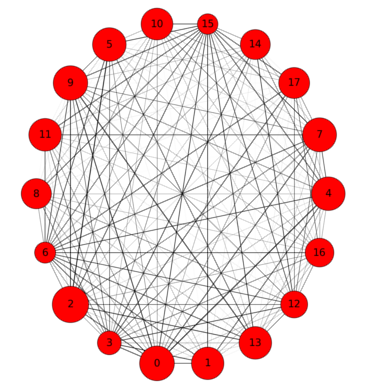
Dezenas de veículos foram incendiados em frente a sede do governo da região de Guerrero, no México, em um protesto pelo desaparecimento e morte de 43 estudantes da escola normal rural de Ayotzinapa. O protesto ocorreu após o procurador-geral da República do país, Jesús Murillo Karam, informar que três homens suspeitos de ser integrantes do cartel Guerreros Unidos confessaram ter matado os estudantes e queimado seus corpos. Segundo a Procuradoria-Geral do México, os detidos não disseram quem levou os estudantes e quem era o mandante da emboscada.
Finale
Este aqui é só um exemplo de como funciona a sumarização de texto usando grafo. Numa implementação pra valer seria melhor implementar o TextRank ou algum outro bom algorítimo, não este nosso aqui, como algorítimo de pontuação e utilizar algumas técnicas, como remoção de sufixos entre outras, para melhorar o desempenho do algorítimo. Além disso, em textos jornalísticos, temos que ter cuidado com as aspas6 incluídas no texto, com entrevistas, com listas… Na verdade, numa implementação real há bastantes detalhes a serem levados em consideração. E tenho a impressão de que pra cada implementação, com um foco diferente, os detalhes de implementação serão diferentes também.
Mas, independentemente dos detalhes de implementação, a ideia geral de sumarização extrativa por grafos está aí. Crie um grafo com as unidades de texto que melhor representam o texto para a tarefa em questão, pontue os nós de acordo com o algorítimo escolhido e por fim extraia os nós mais bem pontuados e é isso. Molezinha, não?
Notas
1 Os métodos melhores avaliados foram o SuPor-2 [3] e o TextRank [4].
2 Apesar de ser um algorítimo multi-idioma, o TextRank alcança seus melhores resultados quando utilizadas algumas técnicas de refinamento específicas para um idioma (stemmerização, stopwords e outros)[2][3].
3 A escolha de um método baseado em grafos se deve principalmente à facilidade de implementação, já que estes métodos dependem somente da análise do texto em questão
4 A simplificação feita aqui em relação ao TextRank é que o nosso algorítimo leva em consideração somente as relações, contrariamente ao TextRank que também leva em consideração, além das relações, a pontuação dos nós com que estas relações são construídas. Pode-se imaginar um algorítimo deste tipo como sendo uma ‘recomendação’ de nós, um nó ‘recomenda’ o outro. O nosso algorítimo simples leva em consideração a quantidade e a ‘força’ das recomendações, o TextRank, além disso, leva em conta também quem está recomendando.
5 Aqui há dois problemas que geralmente passam ao largo nas descrições dos algorítimos de extração: temos que decidir o tamanho do resumo e temos que, depois de extrair as sentenças de acordo com a pontuação, re-ordenar as frases de acordo com a ordem no texto-fonte. Re-ordenar as sentenças é trivial, e para o tamanho do resumo usaremos um tamanho de 20% o número de sentenças do texto original.
6 As aspas são citações da fala de alguém. É comum termos aspas que contém mais de uma sentença e não é bom cortas as aspas em sentenças, sob o risco de alterar completamente o sentido da frase proferida.
Referências
[1] Martins, C.B.; Pardo, T.A.S.; Espina, A.P.; Rino, L.H.M. (2001) – Introdução à Sumarização Automática.
[2] Margarido, P.R.A.; Pardo, T.A.S.; Aluísio, S.M. (2008) – Sumarização Automática para Simplificação de Textos: Experimentos e Lições Aprendidas.
[3] Leite, D.S. & Rino, L.H.M (2006) – Uma comparação entre sistemas de sumarização automática extrativa.
[4] Mihalcea, R. (2004) – Graph-based Ranking Algorithms for Sentence Extraction, Applied to Text Summarization
[5] Mihalcea, R. & Tarau, P. (2004) – TextRank: Bringing Order into Texts
[6] Python Programming Language – https://www.python.org/
[7] Natural Language Toolkit – http://www.nltk.org/
[8] NetworkX – https://networkx.github.io/
